Architecture
The Stakeholder Agent System follows a multi-tier web application architecture designed for reliability, responsiveness, and ease of evolution. The system separates concerns across distinct tiers: a browser-based front-end application and a backend AI service handling prompt orchestration. External platform services provide authentication, data storage, and cloud hosting. A privately hosted Large Language Model (LLM) serves as the AI provider.
Data Flow:
- Users interact with browser-based chat interface
- Front-End authenticates users via Neon Auth
- User messages sent to the AI Service via REST API
- FastAPI validates request JWT with Neon Auth and extracts user context
- AI Service leverages Pydantic AI agent for prompt orchestration, context management, and guardrails
- AI service calls LLM provider to generate responses
- Request and Response persisted to Neon Postgres for durability
- Response propagated back to the UI for display
Infrastructure:
- All session data and chat history persist to Neon Postgres (external)
- Authentication through Neon Auth, injected into frontend TanStack router and backend FastAPI service (external)
- CI/CD pipelines: lint, typecheck, test, build, and deploy backend and frontend services to GCP with GitHub Actions
- Cloud hosting on Google Cloud Platform (GCP) with managed services for compute and networking
C4 Model Diagrams
Level 1: Context Diagram
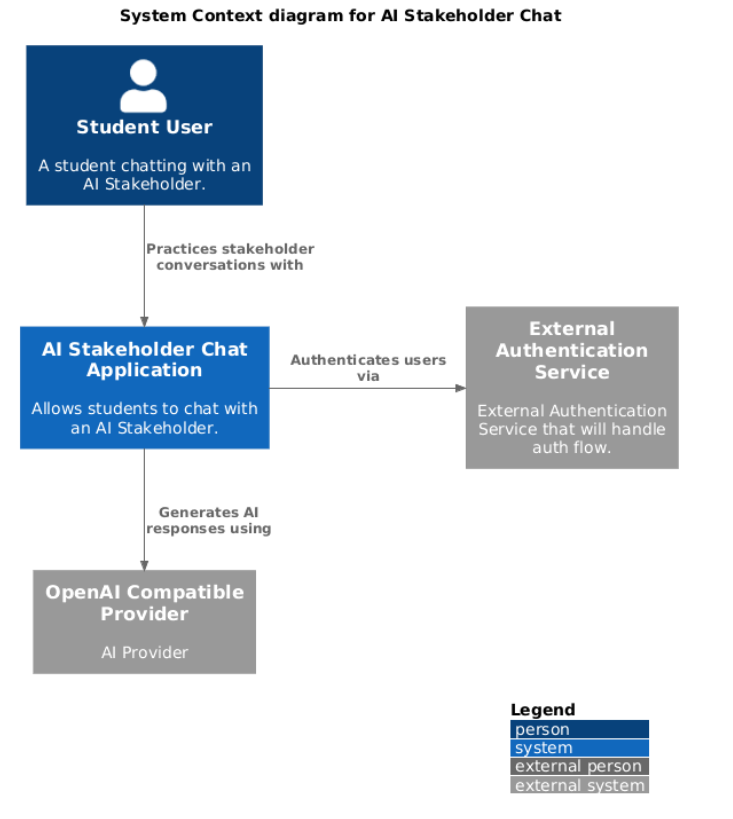
Level 2: Container Diagram
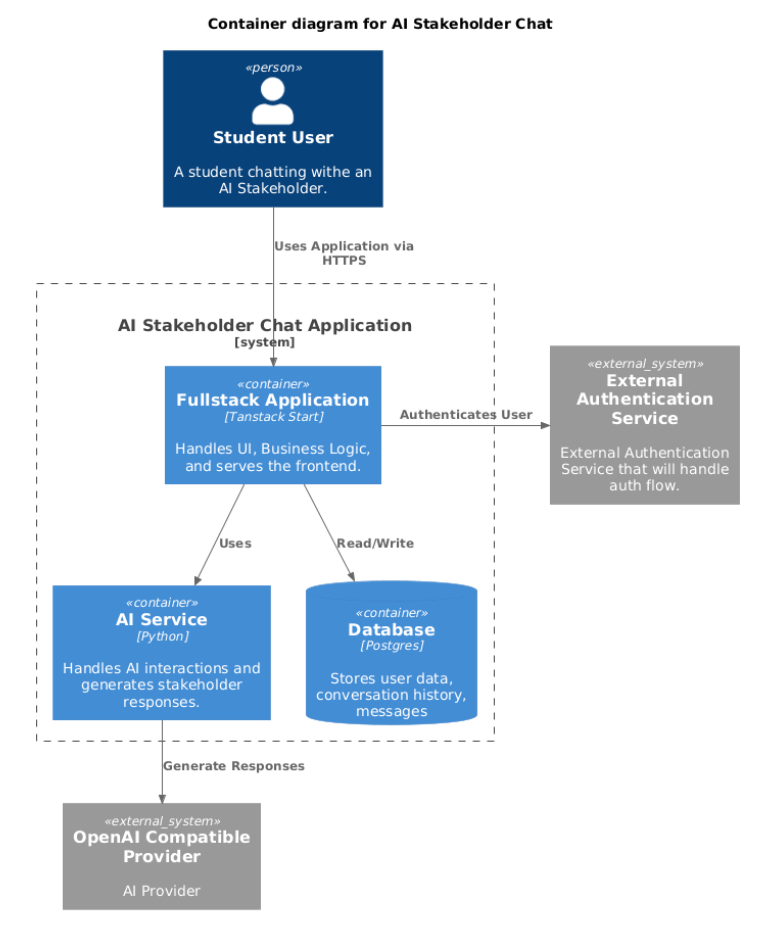
Level 3: Component Diagrams
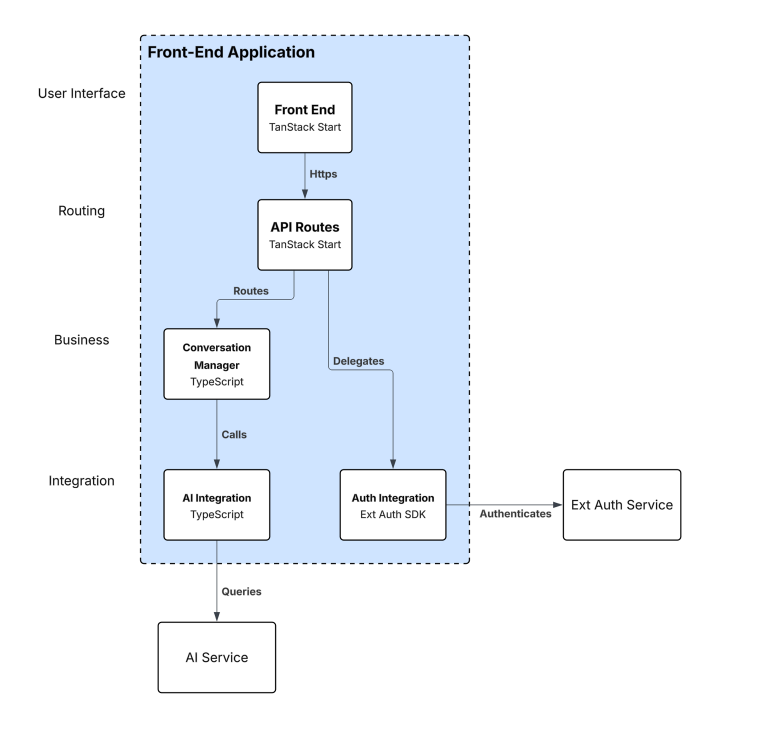
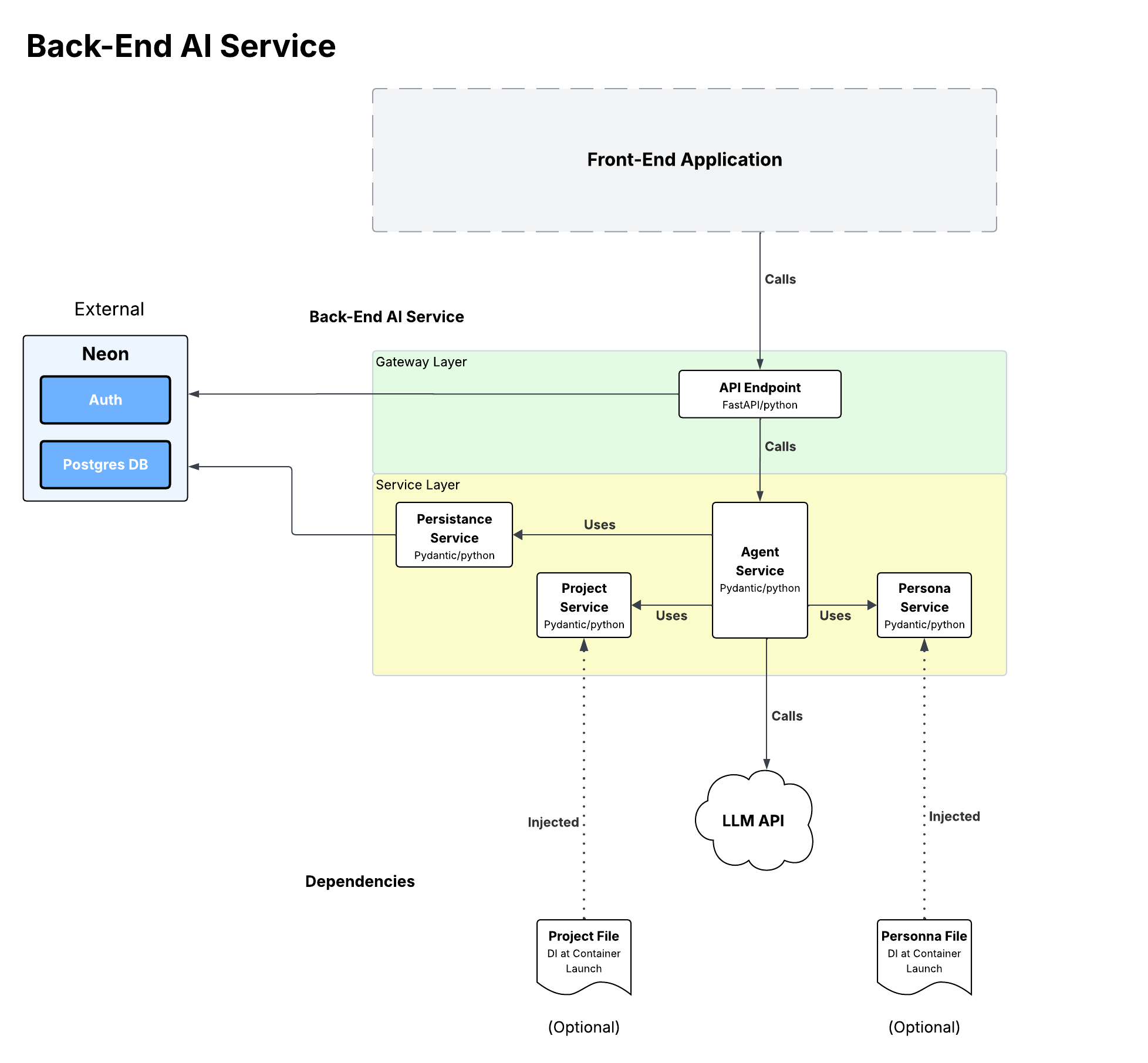
Level 4: Class Diagrams

Key Components
Front-End Application
The browser-based web application provides the primary user interface for stakeholder interactions. Built with TypeScript and TanStack Start, and Node. It delivers a responsive chat interface that enables natural conversational flow during requirements elicitation sessions.
Responsibilities:
- Render the conversational chat interface
- Manage client-side session state
- Handle user authentication flows
- Display captured requirements and session history
AI Service
The Python-based backend service serves as the central orchestration layer for all AI-powered interactions. Built with Pydantic AI and FastAPI, it manages the complexity of prompt engineering, context management, and integration with external AI providers.
Responsibilities:
- AI prompt orchestration and context assembly
- Input validation and AI guardrails
- Rate limiting and token budget management
Data Store
Neon Postgres provides durable persistence for all application state. As a serverless Postgres platform, Neon ensures session continuity and enables recovery from service interruptions while offering scalable, managed database infrastructure.
Persisted Entities:
- User accounts and profiles
- Session metadata and configuration
- Complete chat history
External Platform Services
Neon Auth: Handles identity verification, session management, and token management, allowing the system to delegate security concerns to a specialized service integrated with the Neon platform.
AI Provider: Organizationally managed oLlamma instance Large Language Model.
Cloud Hosting: Google Cloud Platform infrastructure provides scalable compute, storage, and networking capabilities.
Architectural Drivers
Three primary quality attributes drive the architectural decisions in this system:
Availability and Reliability
Session durability is critical for a practice environment where users invest significant time in requirements elicitation conversations. The architecture addresses this through:
- Stateless backend design - The AI Service maintains no in-memory state, enabling horizontal scaling and seamless recovery
- Durable data tier - All session state persists to Neon Postgres before acknowledgment
- Cloud hosting - Google Cloud Platform provides infrastructure resilience and health monitoring
Performance
Responsive conversational interaction is essential for maintaining natural dialogue flow. The target is response delivery within 5 seconds for 95% of requests.
- Asynchronous AI calls - Non-blocking I/O prevents thread starvation during LLM inference
- Connection pooling - Database connections are reused to minimize latency overhead
- Token budgeting - Context windows are managed with a history summarizer agent component to balance response quality with latency
Modifiability
The system must evolve to support new stakeholder personas, project scenarios, and potentially different AI providers.
- Externalized configuration - Personas and scenarios are data-driven, not hard-coded
- AI provider abstraction - Pydantic AI’s agent model allows for pluggable provider integration, enabling future substitution without service changes
- Modular boundaries - Clear separation between tiers enables independent evolution
Quality Attributes
Performance Tactics
| Tactic | Implementation |
|---|---|
| Async I/O | Non-blocking calls to AI provider and database |
| Connection Pooling | Reusable database connections minimize connection overhead |
| horizontal Scaling | Stateless design allows adding cloud instances to handle load |
| Rate Limiting | Request throttling prevents system overload |
Availability Tactics
| Tactic | Implementation |
|---|---|
| Exponential Backoff | Retries with increasing delays for transient failures |
| Circuit Breaker | Fast failure when AI provider is unresponsive |
| Health Checks | Continuous monitoring of service and dependency health |
| Reliable State Storage | Session state persisted to Neon durable storage |
Security Tactics
| Tactic | Implementation |
|---|---|
| RBAC | Role-based access control for authorization |
| Data Isolation | Tenant-level separation of session data |
| TLS | Encrypted communication for all network traffic |
| Input Validation | Sanitization of all user inputs |
| AI Guardrails | Content filtering and prompt injection prevention |
Modifiability Tactics
| Tactic | Implementation |
|---|---|
| Data-Driven Configuration | Personas and project scenarios stored as configuration data |
| Layered Architecture | Clear boundaries between presentation, service, and data tiers |
| Provider Abstraction | Pluggable interface for AI provider integration |
Technology Stack
For a detailed breakdown of technologies used in this system, see the Technology Stack page.
Key Design Decisions
Stateless Backend Architecture
The AI Service maintains no in-memory session state. All state is persisted to the data tier, enabling:
- Horizontal scaling without session affinity
- Simplified recovery from service restarts
- Consistent behavior across service instances
Delegated Authentication
Authentication is handled by Neon Auth rather than a custom implementation. This approach:
- Reduces security implementation burden
- Leverages proven identity management infrastructure
- Simplifies compliance with security standards
- Integrates seamlessly with the Neon Postgres data tier
REST Communication Pattern
The front-end and AI service communicate via REST APIs with JSON payloads. This provides:
- Clear contract definition between tiers
- Familiar patterns for development teams
- Broad tooling support for testing and debugging
Single Service Design
The backend is implemented as a single logical service rather than decomposed microservices. For the current scope, this approach:
- Reduces operational complexity
- Simplifies deployment and monitoring
- Avoids premature optimization for scale not yet required
The architecture supports future decomposition if scaling requirements change.
Next Steps
| Goal | Documentation |
|---|---|
| Review technology selections | Technology Stack |
| Set up local environment | Getting Started |
| Understand API contracts | API Documentation |
| Start building features | Implementation Guidance |